Ch6. Synchronization Tools
목표
- 임계구역 문제와 경쟁 조건
- 메모리 경계, compare-and-swap 연산, atomic 변수를
사용하여 임계 구역 문제의 하드웨어 솔루션 - mutex locks, sempahores, monitors and condition variables를 이용하는 법
임계구역 문제
n개의 프로세스 존재하는 상황
하나의 프로세스가 임계구역에 들어갔을 때,
다른 프로세스들이 임계구역에 들어가면 안된다.
Critical section problem은 위 상황을 해결하는 프로토콜을 디자인 하는 것이다.
- 프로토콜 흐름
- entry section
- critiacl section
- exit section
- remainder section
해결법
- Mutual Exclusion (상호배타)
- 어떤 프로세스
P_i가 임계구역에 있으면, 다른 프로세스들은 임계 구역에 없다.
- 어떤 프로세스
- Progress
- 임계구역안에 실행 중인 프로세스가 없고 임계구역에 들어가고 싶은 프로세스가 있을때, 다음 프로세스 선택이 무기한 연기될 수 없다.
- Bounded Waiting
- 임계구역을 요청하고 허락받는 동안 다른 프로세스에게 양보해야 하는 횟수의 상한선이 있어야한다.
OS에서 임계구역 다루기
커널이 선점, 비선점인지에 따라 두가지 접근법이 존재한다.
- Preemptive
- 커널 모드에서도 다른 프로세스가 선점되어 CPU를 차지할 수 있음.
- 현대 대부분 선점형 커널을 이용
- 장점 : 속도가 빠름
- 단점: 동시성 문제 때문에 race condition 방지 설계가 매우 어렵다 특히 SMP (다중 CPU) 구조에서는 설계 난이도 높음
- Non-Preemptive
1
2
3
4
5
6
7
8
9
while (true) {
flag[i] = true; // flag[i]는 i가 cs에 들어갈 준비가 되었음을 나타냄
// turn은 j에게 우선 양보
turn = j;
// i는 flag[j] = false 또는 turn = i이면 CS 들어감 (상호배타)
while (flag[j] && turn == j) ;
/* Critical Section */
flag[i] = false;
/* Remainder Section */
현재 안쓰는 이유
위 방법이 현재 컴퓨터에서 보장이 되지 않는다.
-> 컴파일러가 최적화하는 과정에서 코드를 재배치해서 우리가 원하는대로 동작이 안됨
동기화 하드웨어
많은 시스템은 임계구역에 대해 하드웨어 지원을 해준다.
- 하드웨어 지원
- Memory barriers
- Hardware instructions
- Atomic variables
Memory Barriers
컴퓨터 아케텍처가 메모리 접근 순서를 보장하는 규칙
- Memory model의 종류
- Strongly ordered
- 다중코어에서 메모리의 값을 변경하면 즉시 다른 곳에서도 확인 할 수 있는 것
- Weakly ordered
- 메모리의 값을 변경하여도 즉시 보이지 않는 것
정의:
메모리 바리어는 현재까지의 load/store 명령이 완료될 때까지 그 이후의 load/store를 지연시키는 명령.
- 메모리의 값을 변경하여도 즉시 보이지 않는 것
정의:
- Strongly ordered
Hardware Instructions
세가지 instruction이 존재함.
- Test-and-Set instruction
- Compare-and-Swap instruction
- Compare-and-Exchange instruction
Test-and-Set Instruction
1
2
3
4
5
6
7
8
9
10
11
12
/*
* rv (return value)가 ture이면 임계구역에 있다는 의미.
* rv가 false면 cs에 아무도 없다는 의미, lock을 이미 true로
* 만들었지 때문에 다른 프로세스가 임계구역에 들어오지 못함.
* 따라서 자신이 임계구역에 들어감.
*/
boolean test_and_set (boolean *target)
{
boolean rv = *target;
*target = true;
return rv;
}
- 원자적으로 실행
- 파라미터의 원래 값을 리턴
- 파라미터의 값을
true로 세팅
example
1
2
3
4
5
6
7
8
9
bool lock = false;
do {
while (test_and_set(&lock))
/* do nothing */;
/* critical section */
lock = false;
/* remainder section */
} while (true);
장점 : 빠르고 간단함.
단점 : 무조건 true로 덮어씀, busy-waiting에서 기아 상태 발생 가능성 있음.
compare_and_swap Instruction
1
2
3
4
5
6
7
8
9
10
11
12
13
14
/*
* value가 예측 (expected) 값과 같으면,
* 새로운 (new_value) 값으로 변경.
* 다르면 변화가 없음.
* value의 원래 값을 항상 리턴함.
*/
int compare_and_swap(int *value, int expected, int new_value) {
int temp = *value;
if (*value == expected)
*value = new_value;
return temp;
}
example)
1
2
3
4
5
6
7
8
9
int lock = 0; // shared integer
while (true) {
while (compare_and_swap(&lock, 0, 1) != 0)
/* do nothing */ ;
/* critical section */
lock = 0;
/*remainder section */
}
장점 : 조건부 update 가능
compare_and_exchange Instruction
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// 원자적으로 실행됨.
1. value가 예측 값과 일치하면,
2. 새로운 값으로 바꾸고 true를 리턴
3. 예측값이 틀리면 예측값을 value로 수정하고 false를 리턴함.
bool compare_and_exchange(int *value, int *expected, int new_value) {
if (*value == *expected) {
*value = new_value;
return true;
} else {
*expected = *value;
return false;
}
}
example)
1
2
3
4
5
6
7
8
9
10
int lock = 0; // shared integer
while (true) {
int expected = 0;
while (!compare_and_exchange(&lock, &expected, 1))
expected = 0 ;
/* critical section */
lock = 0;
/*remainder section */
}
Example: Bounded-waiting Mutual Exclusion with compare-and-swap
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
while (true) {
waiting[1] = ture; // waiting[i] 는 다름 프로세스가 cs에 있으니 i는 대기
key = 1;
// key는 lock의 현재 값, key = 1 lock 상태임.
// waiting[i] = false면 누군가 cs에서 나왔고, i가 cs에 들어갈 수 있음.
// key = 0이면 lock이 풀렸다가 다시 걸렸으므로 i가 cs에 들어갈 수 있음.
while (waiting[i] && key == 1)
key = compare_and_swap(&lock, 0, 1);
waiting[i] = false;
/* critical section */
j = (i + 1) % n;
while ((j != i) && !waiting[j])
j = (j + 1) % n;
if (j == i) // 아무도 기다리는 프로세스가 없음. lock 해제
lock = 0;
else
waiting[j] = false;
// cs에 들어가기를 기다리는 프로세스가 있어서 lock을 건 상태에서 들어가도록 함.
// lock을 물려주는 효과.
}
Atomic Variables
다중 스레드/프로세스 환경에서도 끼어들기(interrupt) 없이 안전하게 조작할 수 있는 변수 integer와 boolean 타임을 제공해줌.
C 사용 예시)
1
2
3
4
#include <stdatomic.h>
atomic_int count = 0;
atomic_fetch_add(&count, 1); // 내부적으로 lock cmpxchg 같은 명령어로 컴파일됨
Atomic Compare & Exchange (in c11)
1
2
_Bool atomic_compare_exchange_weak(_Atomic(T) *object, T *expected, T desired);
_Bool atomic_compare_exchange_strong(_Atomic(T) *object, T *expected, T desired);
- If object == expected, then object = desired, return true
- If object != expected, then expected = object, return false
Weak 버전 : object가 expected와 같아도 false를 주는 거짓부정이 가능. (cpu의 최적화, 메모리 일관성 등으로 발생 )
그러나 발생 확률이 낮고 빠르기 때문에 거짓으로 판단해도 해가 없는 while 문 안에서 사용함.
Strong 버전 : 거짓이 없으나 느리다. if 문 안에서 사용함
Mutex Locks
이전 까지의 하드웨어 기반 솔루션들은 어플리케이션 개발자들에게는 복잡하고 일반적으로 접근이 불가능하다. OS 개발자들이 소프트웨어 도구를 만들어뒀다.
💡
spinlock은 cpu를 소모하지만 context swithcing이 필요없어서 유리한 면도 있다.
lock에 대한 경쟁이 낮은 다중 코어 또는 다중 프로세서 환경에서는 spinlock의 성능이 우수하다. (kernel). 일반 적으로 lock을 걸고 있는 시간이 두 개의 context switing 시간보다 작으면 spinlock이 유리하다.

Semaphore
세마포어는 프로세스가 동기화할 수 있도록, 뮤텍스보다 더 정교한 방식을 제공하는 동기화 도구이다.
여러 프로세스나 스레드가 공유 자원을 제한된 개수만큼만 사용하도록 제어하는 동기화 도구
- Counting semaphore: 사용 가능 자원 개수를 가짐
- Binary semaphore: 0, 1 사이의 범위만 사용함 = mutex lock과 동일함.
Semaphore Implementation
하나의 세마포어 S에 대해서 두 개의 프로세스가 동시에 wait(S)나 signal(S)를 실행하면 안 된다. 왜냐하면 S는 정수 값이고, 이것을 동시에 읽고 수정하게 되면 race condition이 발생할 수 있음. wait()과 signal() 함수는 내부적으로 S를 조작하는 코드인데, 이 코드 자체를 보호해야 하니까 →. 이 코드를 임계 구역으로 취급해야 한다. Semaphore는 일반적으로 busy waiting을 하지 않고 waiting queue를 사용해서 구현한다.
구현 방식에 따라, wait()에서 계속 루프를 돌며 lock이 풀리길 기다리는 busy waiting이 발생할 수 있다
- 각 세마포어는 연결된 waiting queue를 가짐
- 대기 큐의 각 항목은 두 가지 데이터를 갖는다.
- value (of type integer)
- pointer to next record in the list
- 두 가지 연산자 존재
- block: 현재 연산을 수행하려는 프로세스를 해당 세마포어의 대기 큐에 넣는다
- wakeup: 세마포어 대기 큐에 있던 프로세스 하나를 꺼내서 ready queue로 이동시킨다
1
2
3
4
typedef struct {
int value; // 세마포어 값이 -n 이면 n 명이 대기 중임
struct process *list; // 세마포어를 기다리는 스레드 대기열
} semaphore;
wait()과 signal()의 구현
❗️주의 인터럽트를 차단 -> 이 정보가 cpu 레지스터에 저장 context switch를 할때 이 모든 내용을 저장하고 새로운 친구를 loading하는데, 이때 인터럽트를 차단했던 상태가 똑같이 불러와지지 않는다.
1
2
3
4
5
6
7
8
9
10
// S->value > 0이면 cs에 들어갈 수 있음
wait(semaphore *S) {
disable interrupts;
S->value--;
if (S->value < 0) {
add this process to S->list;
block();
}
enable interrupts;
}
1
2
3
4
5
6
7
8
9
signal(semaphore *S) {
disable interrupts;
S->value++;
if (S->value <= 0) {
add this process to S->list;
wakeup();
}
enable interrupts;
}
단일 CPU에서는 interrupt disable을 통해 wait()와 signal()의 원자성을 구현할 수 있다. 그러나 다중 코어시스템에서 모든 코어의 interrupt를 막는 것은 손해가 많다. 따라서 spinlock을 사용하여 다른 코어와 공유하는 세마포 데이터의 상호배타를 보장한다.
Monitors
고수준 추상화로 프로세스간 동기화를 간편하고 효과적으로 해주는 수단이다. 모니터는 ADT 처럼 내부 데이터를 외부에서 접근 불가하게 보호한다. 반드시 모니터 내부의 함수들을 통해서만 접근 가능 -> 캡슐화 느낌쓰
모니터 안에는 항상 하나의 프로세스만 실행 가능하다.
조건 변수
가능한 두가지 동작
- wait()
- 이 함수를 호출하면, 그 스레드는 즉시 멈춰서 대기열로 들어감
- cpu 사용 X
- signal()
- 이 함수를 호출하명, wait()로 기다리고 있던 스레드 중 하나를 깨운다.
- 만약 아무도 기다리고 있지 않다면 -> 아무 일도 안 일어남
프로세스는 모니터 안에서 함수를 방해받지 않고 실행할 수 있는 것을 보장받는다.
만일 다른 프로세스의 병행실행을 허용하고 싶으면 조건 변수에 wait()을 실행함으로써 가능하다.
즉, 프로세스가 preemption 위치를 스스로 지정할 수 있음을 뜻한다.
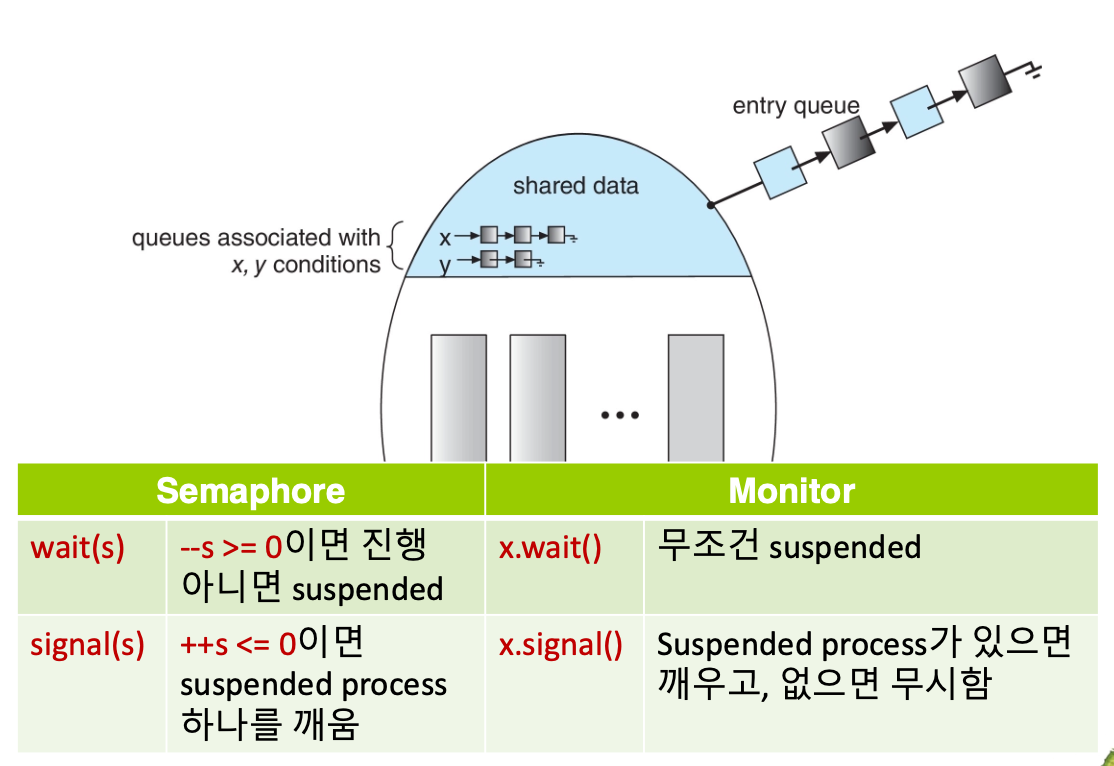
Monitor 구현
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
semaphore mutex = 1;
condition x;
x.sem = x.count = 0;
semaphore next = 0;
next_count = 0;
function F (...)
{
wait(mutex);
...
body of F
...
if (next_count > 0)
signal(next);
else
signal(mutex);
}
x.wait()
{
x.count++;
if (next_count > 0)
signal(next);
else
signal(mutex);
wait(x.sem);
x.count--;
}
x.signal()
{
if (x.count > 0) {
next_count++;
signal(x.sem);
wait(next);
next_count--;
}
}