Ch5. CPU Scheduling
목표
- 다양한 CPU 스케줄링 알고리즘에 대해
- CPU 스케줄링 알고리즘 평가
- 멀티프로세서와 멀티코어 스케줄링
- 다양한 실시간 스케줄링 알고리즘
- windows와 linux 운영체제의 스케줄링 알고리즘
1. 스케줄링의 기본 컨셉
- CPU 사용률 최대화 (멀티 프로그래밍을 통해서)
- CPU-I/O Burst Cycle
- CPU burst -> I/O burst 순서
- CPU Burst 분포가 중
2. CPU Scheduler
CPU 스케줄러는 ready queue에 있는 프로세스 들중 선택한다. 그후 CPU 코어를 할당해준다.
CPU 스케줄링은 프로세스의 상태 변화에 따라 필요하다
- running -> waiting state
- running -> ready state
- waitin -> ready
- treaminates
CPU 스케줄링의 종류
- nonpreemptive (비선점) - 위의 1, 4번의 상황 -> 종료나 waiting 상태가 아니면 CPU를 놓치 않음 -> 결국 그냥 CPU를 계속 가지고 있는거임
- preemptive (선점) - 위의 2, 3번의 상황
-> CPU를 한정된 시간 동안만 할당
- 공유 데이터 접근을 고려 -> race condition 발생가능
- 커널 모드인 동안 선점을 고려
- 중요한 OS 작업중에 인터럽트가 발생하는 상황을 고려 -> 불가피할 경우 인터럽트를 disable 했다가 끝나고 enable도 가능
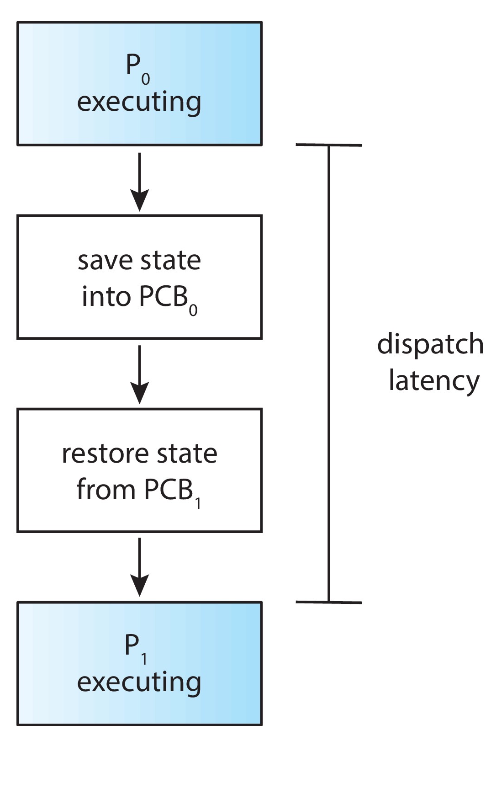
2-1. Disipatcher
스케줄러 내에 task의 실행 순서를 제어하는 역할 단기 스케줄러가 선택한 프로세스를 CPU에 할당하는 기능ready -> running
2-2. 스케줄링 최적화 기준
- CPU 이용률 최대
- 처리량 최대
- 반환시간 최소
- 대기 시간 최소 (ready queue에서 머무는 시간)
- 응답 시간 최소
-> 반환시간이 같아도 응답시간이 짧으면 결과를 미리 볼 수 있는 효과가 있다.
-> 응답시간의 평균을 줄이는 것보다 편차를 줄이는 것이 일반적으로 더 중요한다.
앞으로 나오는 cpu 스케줄링 알고리즘의 성능 평가는 평균 대기시간으로 할거임.
3. Scheduling Algorithm
3-1 First-Come, Fist-Served (FCFS) 스케줄링
말 그대로 먼저온걸 가장 먼저 처리해준다.
- example) 한 번의 CPU 사용과 하나의 코어 사용을 가정
- P1 : 24, P2 : 3, P3 : 3 이 순서 대로 들어 올때
- 대기 시간 => P1 : 0, P2 : 24, P3 : 27
- 평균 대기 시간 -> (0 + 24 + 27) / 3 = 17
- P2 : 3, P3 : 3, P1 : 24 이 순서 대로 들어 올때
- 대기 시간 => P1 : 6, P2 : 0, P3 : 3
- 평균 대기 시간 -> (6 + 0 + 3) / 3 = 3
- 아까랑 같은 양을 처리하지만 더 빠름 -> Convoy effect : 긴 cpu-bound job 때문에 짧은 job이 계속적으로 cpu를 기다리는 현상
3-2 Shortest-Job-First (SJF) 스케줄링
= Shortest-next-CPU-burst Algorithm 각 프로세스마다 “다음에 CPU를 얼마나 사용할지” 길이를 연결해서 기억해줌 -> 그리고 CPU를 가장 짧게 사용할 것 같은 프로세스부터 스케줄링해서 실행한다. -> SJF는 최적이다. 가장짧은 평균 대기 시간을 만들어준다. -> 근데 구현하기가 어려움…
- example) 동시에 도착했다고 가정
- p1 : 6, p2 : 8, p3 : 7, p4 : 3
- 처리 순서 : p4 -> p1 -> p3 -> p2
- 평균 대기 시간 : (3 + 16 + 9 + 0) / 4 = 7
3-2-1 그럼 다음 CPU Burst 길이를 어떻게 알 수 있을까?
실제로는 다음 cpu 사용 시간이 얼마인지 정확히 알 수 없다. 대신 이전 cpu 사용시간을 보고 비슷할 거라고 추축한다. 그리고 가장 짧을 것 같은 프로세스슬 선택해서 실행 에측하는 방법 : 지수평균법
3-2-2 SJF의 종류
- Nonpreemptive SJF : 새로 도착한 job이 현재 실행 중인 job보다 짧아도 기다려야함
- Preemptive SJF : 새로 도착한 job이 현재 남아 있는 job보다 짧으면 교체 = Shorest-remaining-time-first (SRTF)
3-3 Round Robin (RR) 스케줄링
FCFS + preemption 느낌 모든 프로세스는 CPU를 사용할 때 아주 짧은 시간 조각 만큼만 쓸 수 있다. (10~100 ms 정도) 이 시간이 지나면 현재 프로세는 강제로 멈춤고 ready queue로 가야한다.
- 작동 방식
- n개의 프로세스, 타임 퀀텀 q
- 각 프로세스는 cpu를 1/n 비율로 번갈아가며 사용
- 최대 q까지 사용가능 -> 이후 전환
- 타이머 인터럽트가 매 time quantum 마다 발생해서, 다음 프로세스로 강제로 스케줄 교체
- 성능
- q가 크면 -> FCFS 처럼
- q가 작으면 -> 너무 자구 교체, context switch 오버헤드가 너무 커짐
- 적당한게 최고!
3-3-1 그럼 time quantum은 어떻게 설정함?
그냥 경험적으로 설정 전체 CPU burst의 80%가 타임 퀀텀보다 짧게 끝나도록 설정함
3-4 Priority 스케줄링
각 프로세스마다의 우선순위가 부여된다.
cpu는 가장 우선순위가 높은 프로세스에게 할다된다.
선점형, 비선점형 모두 가능하다.
SJF는 사실상, “다음 CPU Burst 시간 예측값을 역으로 해석한” 우선순위 스케줄링이다.
- 문제점
- 기아 현상 : 우선순위가 낮으면 영원히 실행 되지 못할 수 있다.
- 해결법
- 시간이 지남에 따라 점점 우선순위를 높여준다.
3-4-1 Round-Robin과 우선순위 스케줄링의 결합
같은 우선순위에서는 RR 스케줄링 방법을 사용하는 방식이다.
3-5 Multilevel Queue
우선순위 스케줄링을 할때, 각 우선순위마다 별도의 큐를 만든다.
가장 높은 우선순위 큐에 있는 프로세스를 먼저 스케줄링한다.
-> 같은 우선순위 안에서는 RR 방식으로 스케줄링
요새는 실시간 프로세스에 가장 높은 우선순위를 준다.
- 높은 우선순위를 무조건 먼전 실행 할 수 도 있고,
- 큐에 따라 time-slice를 배정할 수 도 있다.
3-6 Multilevel Feedback Queue
프로세스가 큐를 이동할 수 있는 방식이다.
- CPU를 많이 사용하면 아래로 내려보내고,
- 너무 오래 기다리고 있으면 위로 올리기도 한다.
하나의 프로세스가 여러 큐 사이를 이동할 수 있다.
- 큐의 개수 (number of queues)
- 각 큐에 적용할 스케줄링 알고리즘 (scheduling algorithms)
- 프로세스를 언제 승격(upgrade) 시킬지 결정하는 방법
- 프로세스를 언제 강등(demote) 시킬지 결정하는 방법
- 프로세스가 처음 어느 큐로 들어갈지 결정하는 방법 가장 일반적인 CPU 스케줄링 알고리즘이면서, 동시에 가장 복잡한 알고리즘이다.
4. Thread Scheduling
스레드를 지원하는 경우, 프로세스가 아니라 스레드 단위로 스케줄링한다.
Linux, macOS, windows 같은 현대의 OS는 kernel-level 스레드를 스케줄링 단위로 인식한다.
- Many-to-one과 many-to-many 모델에서는 스레드 라이브러리가 유제 레벨 스레드를 LWP 동작하게 한다 -> 가상 프로세스처럼 논리적 뷰를 제공
- 이 경우를 Process-Contention Scope (PCS) 라고 부른다.
- 보통 프로그래머가 설정한 우선순위에 따라 스케줄링
- 커널 레벨 스레드는 CPU가 직접 스케줄링
- System-Contention Scope (SCS)
4-1. Phtread Scheduling
- PTHREAD_SCOPE_PROCESS
- PTHREAD_SCOPE_SYSTEM
- linux랑 macOS는 이것만 허용
4-2 Multiple-Processor Scheduling
- 좀 더 복잡함.
- 멀티프로세스는 아마 아래 중하나의 구조를 따른다.
- 멀티코어 CPU
- 하나의 코어가 다중 하드웨어 스레드를 지원
- NUMA system (Non Uniform Memory Access)
- Hereoeneous multiprocessing
- 모바일 시스템에서 동일한 기능을 하지만 전원을 절약하기 위해 성능이 떨어지는 코어를 추가로 가지고 있는 형
Asymmetric Multiprocessing (AMP)
- 한 프로세서만 스케줄링을 담당하고, 나머지 프로세서는 그냥 일만 한다.
Symmetric Multiprocessing (SMP)
- 모든 프로세서가 스스로 스케줄링한다.
- 서로 대등하게 일을 나눔.
- 요즘 운영체제들은 전부 이 방식
- 공유 큐 (Common Ready Queue)
- 모든 CPU(core)가 하나의 큰 큐를 공유한다.
- 특징:
- Ready Queue를 여러 코어가 같이 쓰기 때문에, -> Race condition(경쟁 상태)이 생길 수 있다.
- 그래서 Locking(락 걸기) 이 필요하다.
- 락 때문에 성능이 떨어지고, 락을 잡으려는 경쟁(high contention)이 발생할 수 있다.
- 개별 큐 (Per-Core Private Queue)
- 각 CPU(core)마다 자기 전용 큐를 가진다.
- 특징:
- 캐시 성능(cache locality) 이 좋아진다. (자주 쓰던 데이터가 계속 같은 코어에 있어서 빠르다.)
- 단점:
- Workload Balancing (부하 균형) 문제가 생긴다.
- 어떤 코어는 바쁘고, 어떤 코어는 한가할 수 있음.
- 그래서 부하 분산 알고리즘이 추가로 필요하다.
4-3 Multicore Processor
최슨 트렌는 한 물리 칩(physical chip) 안에 여러 개의 프로세서 코어(multiple processor cores) 를 넣는다.
- 더빠르고
- 전력 소모도 적음
- Memory Stall을 이용하는 기술:
- CPU가 메모리에서 데이터를 가져오거나 보낼 때 아무것도 못 하고 멈춰 있는(Memory Stall) 시간을, 다른 스레드를 돌리면서 낭비 없이 활용할 수 있다.
- 각 코어(Core) 는 2개 이상의 하드웨어 스레드(hardware threads) 를 가질 수 있다.
- 만약 한 스레드가 메모리 스톨(Memory Stall) 이 걸리면, → 다른 스레드로 바로 전환(switch) 해서 CPU를 쉬지 않고 계속 돌린다.
5. Real-Time CPU Scheduling
- Soft real-time systems : 실시간성이 중요하긴한데, 막 급한거는 아님
- Hard real-time systesms : 이 친구는 바로 처리해야됨
5-1 Priority-base Scheduling
실시간 스케줄리을 위해서, 스케줄러는 선점과 우선순위 기반 스케줄리을 지원한다. 하지만 소프트 리얼타임에만 캐런티를 줌
Admission-Control algotithm :
프로세스가 스케줄러에게 deadline을 요청했을 때
- 받아들여서 주어진 시간내에 종료를 보장하던지
- 또는 불가능하기 때문에 거부하든기 졀정하는 알고리즘
5-2 Rate Monotonic Scheduling
Periodic 프로세스를 스케줄링 static priority policy + preemption 사용
- 짧은 주기 -> 높은 우선순위, 긴 주기 -> 낮은 우선순위
- example) P1: p1 = 50, t1 = 20, d1 = 50 | P2: p2 = 100, t2 = 35, d1 = 100
- Rate-monotonic scheduling 알고리즘은 정적인 우선순위를 사용하는 알고리즘 가운데 optimal 알고리즘이다.
- 또한 이 알고리즘은 N개의 프로세스를 스케줄링할 때 CPU 사용률이 $ N * (2^(1/N) - 1 $ 을 넘을 수 없다.
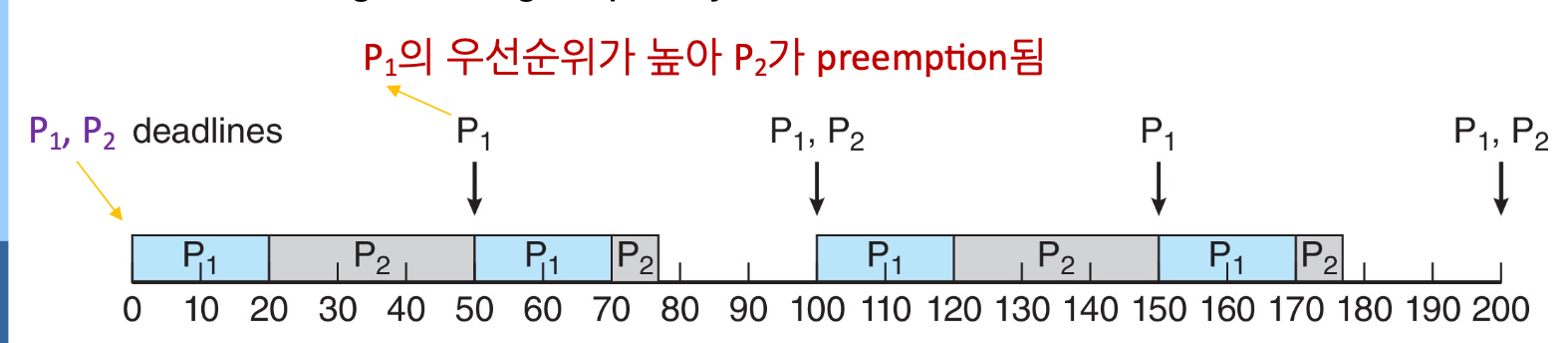
5-3 Earliest Deadline First Scheduling (EDF)
이거는 deadline에 따라 우선순위가 결정이 된다.
- EDF는 프로세스가 주기적일 필요가 없으며 CPU burst가 일정할 필요도 없다.
- 스케줄러에게 deadline을 미리 알려줄 수 있으면 된다.
- EDF는 이론적으로 최적의 알고리즘이다. -> CPU 사용률을 100%까지 올리 수 있다. -> but, 현실은 context switching 등 추가 비용으로 100% 성취할 수 없다.
5-4 Proporional Share Scheduling
각 프로세스가 신청한 비율 만큼 나눠서 쓰게 하는 스케줄링
- 전체 시스템에 CPU를 100개의 share로 나눔
- 각 프로세스는 원하는 만큼의 share를 신청함
- 그리고 자기가 받은 share만큼 CPU를 씀 -> 초과되면 cpu ahtTma
5-5 POSIX Real-Time Scheduling
| 이름 | 뜻 |
|---|---|
| SCHED_FIFO | First-In-First-Out |
| SCHED_RR | Round-Robin |
| SCHED_OTHER | 일반 프로세스용 (비실시간) |
6. Linux Scheduling Trough Ver 2.5
2.5 이후 많은 변화가 있었음
- O(1) 스케줄링 -> 프로세스 개수에 상관없이 스케줄링 시간이 일정함 -> 빠름.
| 항목 | ㅻ챸 |
|---|---|
| 선점형 (Preemptive) | 우선순위 높은 프로세스가 강제로 CPU 뻿을 수 있음 |
| 우선순위 기반 | priority에 따라 실행 순서 결정 |
| 우선순위 2개 영역 | - 실시간 영역 (099) - 일반(time-sharing) 영역 (100140, nice 값 사용) |
| 숫자가 작을수록 우선순위 높음 | - |
| 높은 우선쉬는 더 큰 q | CPU를 더 오래 쓸 수 있음 |
| time slice 다 쓰면 expired로 이동 | 다 쓰면 바로 실행 불가, 다른 애들 다 끝날 때까지 대기 |
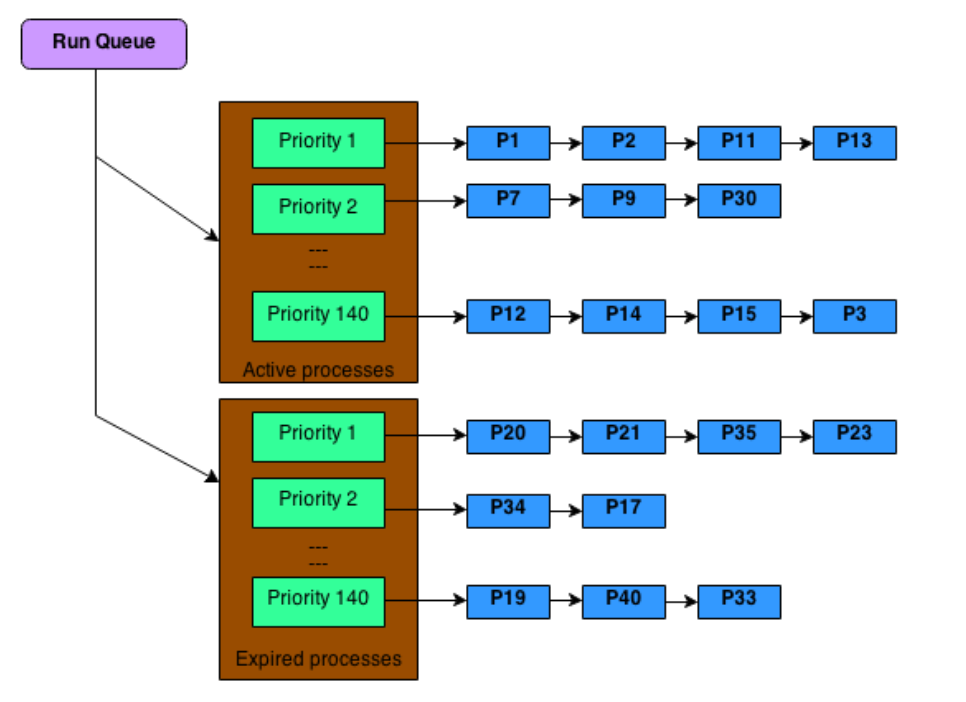
- 데이터 구조: per-CPU runqueue
- runqueue라는 작업 대기열이 따로 존재 (priority array 두개 사용)
- active: 당장 실행 가능 프로세스
- expired: time slice 다 쓴 프로세스
동작흐름
- active 배열에서 높은 우선순위 순서대로 실행
- 실행하다가 time slice 다 쓰면 expired 배열로 이동
- active 배열이 비면, active <-> expired 교체
- 다시 실행!
근데, 인터렉브 프로세스 반응은 별로임
7. Linux 2.6.23+ (CFS: Completely Fair Scheduler)
CFS는 우선순위를 직접 할당하지 않고 virtual runtime에 따라 동적으로 조정.
CFS는 runnable task 중에 vruntine이 가장 작은 것을 먼저 해줌.
- Scheduling classes
- 각각의 클래스는 특정 우선순위를 가짐
- 스케줄러는 가장 높은 스케줄링 클래스 안에서 가장 높은 우선순위의 task를 선택
- CPU 시간 비율에 기반하여 동작
- 기본 클래스 -> CFS를 사용, 실시간 클래스도 존재
- Quantum은 nice value 따라 계산됨
- nice 값이 낮을수록 우선순위가 높음
- target latency를 계산한다. -> runnable한 task가 최소 한 번은 실행되는데 걸리는 총 시간
- CFS 스케줄러는 각 task별로 virtual run time (vruntime)을 유지
- vruntime은 task의 우선순위에 따라 감쇠(decay) 되면서 증가한다.
- nice = 0인 경우, 기본 decay 비율이 적용된다. -> 같은 CPU 시간을 사용해도 우선순위가 낮은 프로세스의 가상 런타임은 높은 프로세스의 가상 런타임보다 크게 계산된다.